Eight engines, weighted to reflect real citation impact
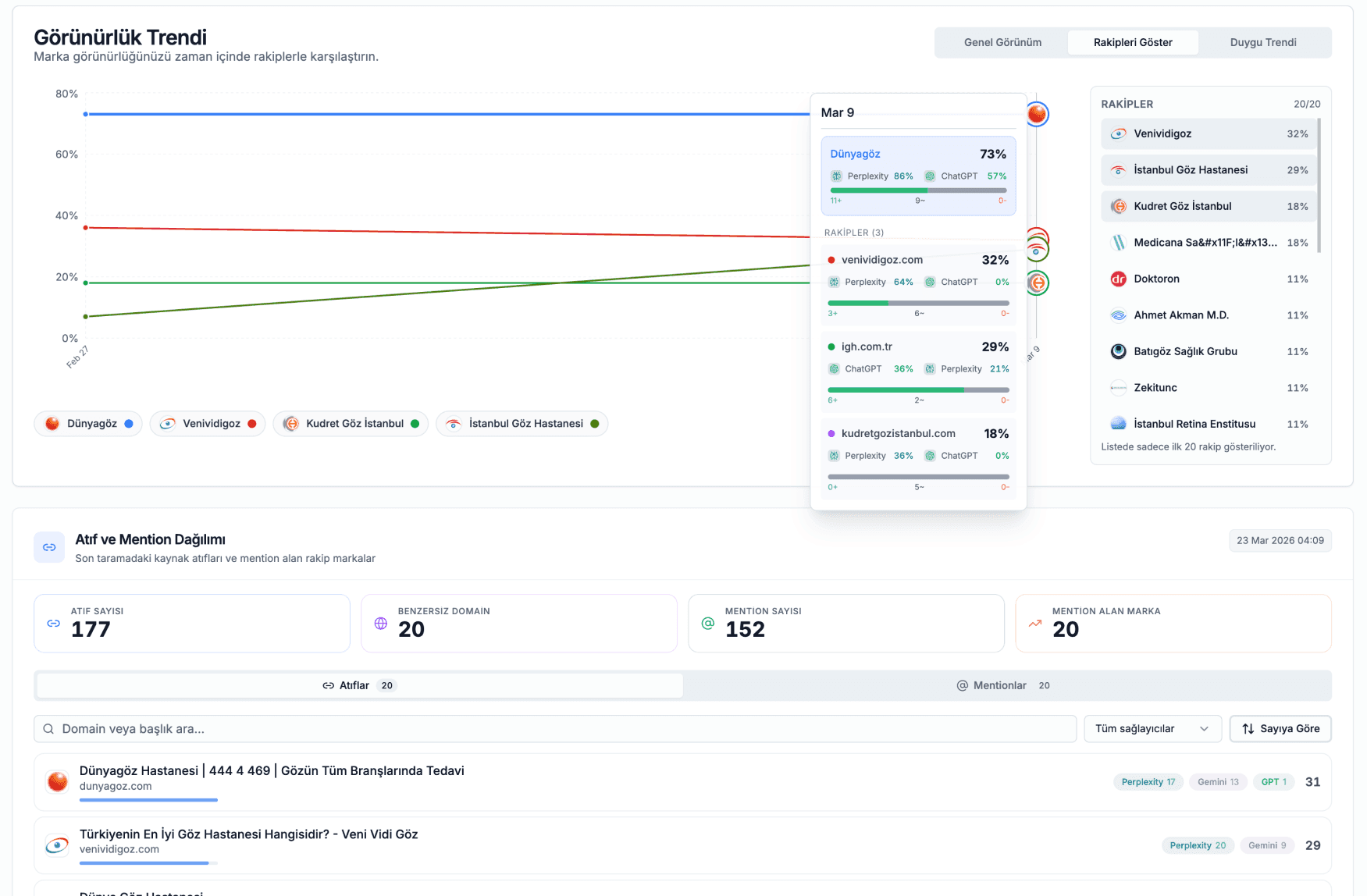
Competitive scoring runs against the same eight AI engines as the visibility module (ChatGPT, Perplexity, Gemini, Claude, Grok, DeepSeek, Meta AI, GLM) but the math is different. Not every engine's citation carries the same revenue impact for your category. The scoring service ships with explicit per-engine weights: Perplexity 1.2, Google 1.1, OpenAI 1.0, Anthropic 0.9, xAI / DeepSeek / Meta 0.8, GLM 0.7.
These weights are deliberate. Perplexity surfaces 4 to 7 sources per response so brand mentions there reach further. Google AI Overviews still routes traffic on top of organic results. DeepSeek and GLM see real volume but in narrower geographic and language contexts. Your brand score (0 to 100) is the weighted total across engines, and your competitive rank (1 = best) is computed against every active competitor in your workspace.
Your market share estimate is your score divided by the total of every active competitor's score plus yours. The trend chart shows up to 12 recent snapshots, about a year of monthly data, so you read the long arc of your share rather than just last week's spike.